
Dopo la lettura del libro blu di Evans mi sono appassionato al Domain-Driven Design. Ero ancora in America quando, con quattro mesi di anticipo, mi iscrissi al workshop Strategic Domain-Driven Design di Alberto Brandolini (aka ziobrando) organizzato da Avanscoperta. Non volevo certo perdermelo.
Poi, preso dal caos di tutti i giorni, avevo perso il senso del tempo quando, a metà ottobre, ho ricevuto una mail da parte di Avanscoperta che mi ha ricordato del corso imminente: è stato come se qualcuno mi avesse regalato un fine settimana alla spa!
Cosa vuol dire sviluppare software?
Una delle prime attività proposte da Alberto è stata quella di definire insieme cosa vuol dire sviluppare software utilizzando altri lavori come metafora. I lavori più gettonati sono stati l’architetto, e l’artigiano, ma ziobrando ne ha proposti alcuni non immediati e molto calzanti:
- l’artificiere: quando siamo chiamati ad intervenire sul codice scritto da qualcun altro il quale “non si occupa più del progetto”;
- il quinto Beatles: ovvero quello che quando va tutto bene non se lo fila nessuno ma che ha tutte le colpe quando qualcosa non va come atteso;
- il fumettista: perché spesso abbiamo scadenze prefissate e dobbiamo cercare di esprimere al meglio la nostra arte nel tempo che abbiamo a disposizione.
La figura dell’artificiere è quella che sicuramente mi ha colpito di più perché ho ripensato a tutte quelle volte in cui sono stato chiamato ad intervenire su applicazioni esistenti dovendo risolvere problemi fantasma senza il supporto di alcun tipo di test. E ripensandoci ora non so come ho fatto a non fare la fine di Dylan nel diciassettesimo episodio della seconda stagione di Grey’s Anatomy!
Questo confronto ha portato Alberto a spiegarci il suo modello dello sviluppo software, la cui magistrale illustrazione riporto qui sotto.
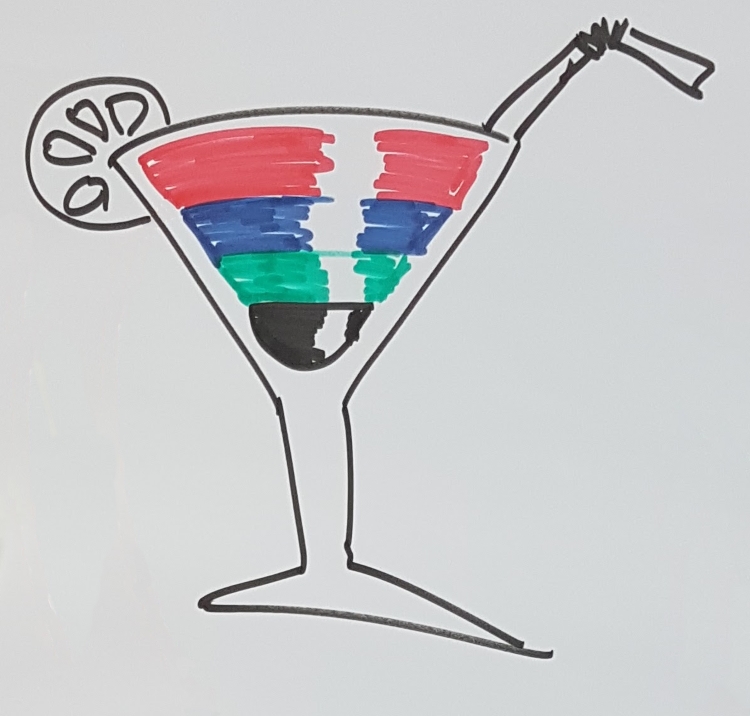
Sostanzialmente lo sviluppo software è un cocktail di quattro componenti: costruire, imparare, decidere e aspettare/nulla.
Costruire: se vogliamo la parte più semplice, e meno divertente, dello sviluppo software, ovvero quando sappiamo esattamente cosa dobbiamo fare, e come dobbiamo farlo. Questa è la parte più deterministica e pianificabile del nostro lavoro. Quella che meglio si adatta ad una gestione stile waterfall. Se non fosse per le altre componenti ogni progetto software potrebbe essere gestito nello stesso modo della costruzione di un palazzo!
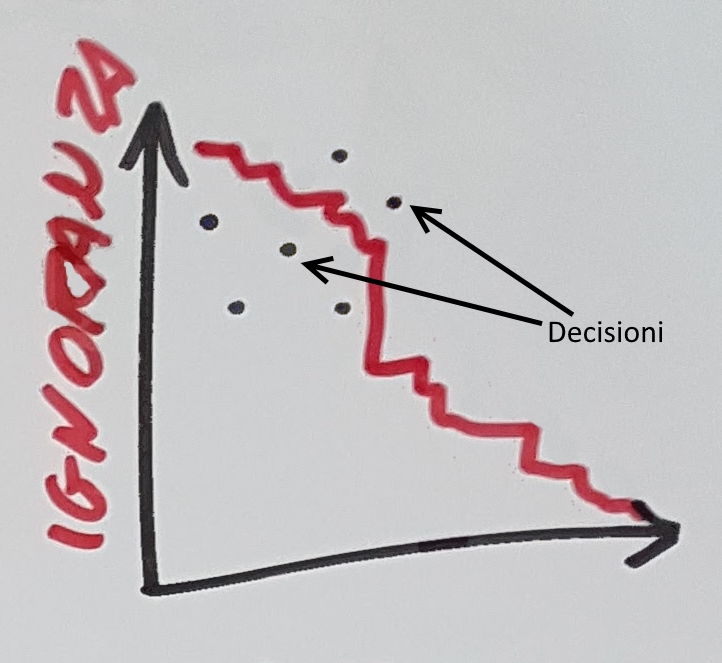
Imparare: quando iniziamo un nuovo progetto la nostra ignoranza è elevata. Ignoriamo cosa serve veramente al cliente, ignoriamo qual è il modo migliore per risolvere il problema, ignoriamo quale sia l’architettura più adeguata. Con l’avanzare del progetto impariamo, o almeno dovremmo imparare, sempre cose nuove e la nostra ignoranza diminuisce. Quello che però molti non sanno è che le persone apprendono di più, e meglio, quando non sono stressate o impaurite, in quanto lo stress e la paura sono inibitori dell’apprendimento. Inoltre l’apprendimento non è lineare con il tempo. Per questo il team di sviluppo deve sentirsi libero di investire il proprio tempo per approfondire gli aspetti più critici del progetto, siano essi tecnici o meno.
Decidere: prendiamo continuamente decisioni, siano esse relative ad un pattern
da utilizzare, all’usabilità di un’interfaccia o all’architettura del sistema. Come
è chiaro dal punto precedente, spesso dobbiamo prendere decisioni avendo solo informazioni
parziali o ignorando parte dei fattori che dovremmo tenere in considerazione nella
nostra decisione. Dobbiamo quindi cercare di metterci sempre nella condizione in
cui le nostre decisioni sono reversibili, e dobbiamo cercare di rimandare le decisioni
critiche all’ultimo momento utile disponibile. Ovvero il momento in cui la nostra
conoscenza è la migliore possibile e la decisione è ancora di valore per il progetto.
Aspettare/Nulla: spesso spendiamo il nostro tempo aspettando qualcuno o qualcosa. Magari aspettiamo perché ci mancano delle informazioni o dei dati di prova. Oppure aspettiamo che qualcun altro finisca uno sviluppo che a noi serve per iniziarne uno nuovo. Tutto questo è ovviamente uno spreco che possiamo, e dobbiamo, ottimizzare. Fortunatamente esistono molte metodologie, e.g. Lean e Kanban, che ci possono aiutare ad affrontare queste problematiche. Aggredire questo tipo di problemi consente di focalizzarci al meglio sulle vere sfide del nostro progetto e di affrontarle al massimo.
Ogni azienda mescola queste quattro componenti a modo proprio. Ovviamente ci sono proporzioni più funzionali ed altre meno. Questo mi ha fatto pensare al Negroni (si, il cocktail) perché utilizzando gli stessi ingredienti si può servire il cocktail del secolo oppure il peggiore stura lavandini possibile!
Strategic DDD in breve
Prima di passare alla parte più interattiva del corso, Alberto ha fatto una breve introduzione sui concetti strategici del DDD e su quando ha senso affrontare un progetto con questa metodologia.
Il DDD richiede un certo impegno in termini di tempo e sforzo da parte del team di sviluppo e del business. Per questo motivo non ha senso applicarlo a tutti i progetti, ma solo a quelli ad alto valore aggiunto: domini complessi e/o in evoluzione. Ovvero i domini nei quali non si può pensare di trovare la soluzione giusta al primo tentativo! In questi casi, lo sforzo richiesto dalla costante raffinazione del linguaggio e dei modelli, propria del Domain-Driven Design, è giustificato dall’aumentata capacità di inseguire i continui cambiamenti dettati dal business.

In progetti così complessi la vera sfida è riuscire a tenere allineato il nostro codice con la nostra comprensione del dominio, ed entrambi con il dominio reale il quale è in continua evoluzione. Se infatti riusciamo a mantenere allineati il codice, e la comprensione che abbiamo di esso, con le esigenze di business, abbiamo la possibilità di rispondere velocemente, e correttamente, ai cambiamenti imposti dal mercato/business. In caso contrario il nostro progetto è destinato a fallire nel momento in cui i cambiamenti saranno troppo repentini per riuscire a soddisfare le nuove richieste in tempi utili. Per riuscire a mantenere l’allineamento necessario il DDD ci mette a disposizione due strumenti molto potenti: Ubiquitous Language e Bounded Context.
Come dice il nome stesso, l’Ubiquitous Language richiede di utilizzare un unico linguaggio onnipresente all’interno del progetto. Il linguaggio, ovviamente, è quello degli esperti di dominio e non quello tecnico. Il codice stesso dovrà riflettere tale linguaggio: in questo modo il codice comunicherà efficacemente il proprio intento e sarà più facilmente comprensibile. Infine, essendoci meno traduzioni fra il linguaggio utilizzato dalle persone di business e quelle tecniche, le comunicazioni saranno estremamente più efficaci.
Purtroppo non è possibile pretendere che all’interno di un’organizzazione tutti utilizzino gli stessi termini con lo stesso significato. Facendo un semplice esercizio di gruppo di classificazione di termini “banali”, è facile constatare che una stessa parola può essere interpretata in modi molto diversi in contesti diversi.
Per risolvere questo problema è indispensabile l’utilizzo dei Bounded Context. Un Bounded Context non è altro che un confine linguistico all’interno del quale siamo sicuri che ogni termine utilizzato ha un solo significato ben definito.
DDD mette al centro dell’attenzione del team di sviluppo l’uso di un linguaggio chiaro e condiviso con il business, il quale sia utilizzato anche nel codice sorgente. Questa affermazione mi ha portato a farmi una domanda: quindi, se stiamo lavorando con degli esperti di dominio che parlano italiano, dobbiamo “programmare” in italiano? La risposta è molto più articolata di quanto possa sembrare! Analizzando il problema con ziobrando sono venute fuori diverse sfumature.
Sicuramente il fatto che i linguaggi di programmazione siano anglofoni (if, for,
getter, setter, etc.) non deve essere un impedimento ad utilizzare i termini del
Ubiquitous Language. Quindi un nome di metodo come SetIndirizzoSpedizione è accettabile
se consente di aumentare la comprensibilità del codice rispetto al dominio per il
quale è stato sviluppato.
Cosa succede se il business parla italiano ma il team di sviluppo no? In questo caso dovremmo trovare una soluzione che consenta di mantenere la comunicazione con gli esperti di dominio efficace e che, contemporaneamente, permetta a chi sviluppa di capire facilmente il codice. Ad esempio, potremmo costruire un glossario condiviso di termini che contenga le traduzioni fra la lingua utilizzata dagli esperti di business e quella utilizzata dagli sviluppatori.
Questo porta ad un altro quesito: siamo sicuri che esista una traduzione per qualsiasi concetto espresso dal business? Per capire meglio la complessità di questo problema prendiamo in considerazione un dominio comune: i documenti fiscali. In Italia utilizziamo il termine fattura per indicare il documento fiscale che viene rilasciato, normalmente fra aziende, a fronte di un servizio sia che il pagamento sia già avvenuto o meno. Normalmente fattura viene tradotto in invoice ma per gli anglosassoni invoice è un documento che viene emesso quando il pagamento non è stato ancora effettuato. In caso contrario loro parlano di receipt che in italiano viene tradotto come ricevuta o scontrino. Pensate poi al concetto di nota proforma, in inglese non riusciamo nemmeno a trovare una traduzione!
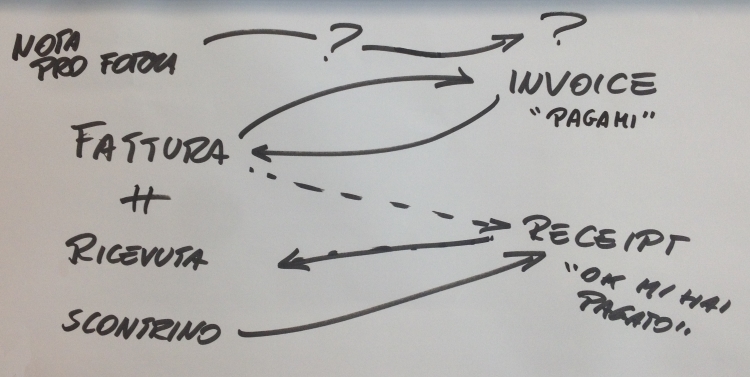
In DDD questi problemi “linguistici” devono ancora essere affrontati sistematicamente. In fin dei conti Eric Evans è americano e probabilmente ha sempre lavorato con team e domini in cui l’inglese era l’unica lingua utilizzata.
Abbiamo appurato che aumentare la conoscenza del team, e adottare un unico linguaggio non ambiguo con il business, sono elementi essenziali per la riuscita di un progetto. Ma che strumenti abbiamo a disposizione per raggiungere questi obiettivi? Per rispondere a questa domanda ziobrando ci ha proposto, e fatto sperimentare, uno strumento di sua invenzione: Big Picture EventStorming.
Big Picture EventStorming
Come recita il sottotitolo del libro di ziobrando, Introducing EventStorming, EventStorming è “un’azione di apprendimento intenzionale e collettivo”. In particolare è uno strumento che consente di esplorare/modellare un intero dominio/business e di condividerne la conoscenza. Se riusciamo a mettere nella stessa stanza le persone che hanno la conoscenza, chi sa fare le domande giuste, e qualcuno che faciliti la discussione, possiamo creare una fotografia condivisa di un intero business la quale può essere utilizzata come strumento decisionale.
Per spiegarci come funziona EventStorming, e per farci assaporare cosa vuol dire partecipare a una vera sessione di modellazione, Alberto ci ha fatto fare un gioco di ruolo: ha scelto un business a lui molto caro, Trenitalia, ci ha fatto scegliere un ruolo da impersonare (capostazione, passeggero, etc.), e ha dato il via ad una vera e propria sessione di modellazione.
Tutto parte con due semplici ingredienti:
- una superficie di modellazione pressoché illimitata, nel nostro caso almeno dieci metri di parete!
- una marea di post-it arancioni, su cui scrivere gli eventi del dominio, con verbi al passato, e che vanno ordinati temporalmente sulla superficie a disposizione.
Senza entrare nei dettagli, per i quali vi consiglio di seguire un workshop di Alberto, dopo quattro ore di lavoro siamo riusciti a modellare una fetta del business di Trenitalia che comprendeva i punti di vista di tutti gli attori coinvolti.

Al di là dell’impressionante impatto visivo, che comunque dà soddisfazione, l’esercizio ci ha permesso di:
- avere chiara l’intera catena del valore e il business dell’azienda attraverso la narrazione fatta tramite gli eventi di dominio;
- catturare la definizione di termini specifici del dominio, post-it a righe posti sotto la superficie di modellazione;
- evidenziare tutte le criticità del sistema, post-it fucsia, siano esse dovute a mancanze, disallineamenti fra funzioni del business, customer experience o altro;
- proporre possibili miglioramenti al sistema, post-it verde acido… per me sono gialli e per questo mi sono sentito daltonico per tutto il workshop!
- identificare chiaramente quali sono le persone coinvolte nei vari flussi, post-it gialli piccoli (con gli omini stilizzati);
- identificare i sistemi esterni con i quali il nostro business si interfaccia, post-it rosa grandi.
Tutte queste informazioni visibili a colpo d’occhio, ci hanno permesso di scegliere quali fossero i problemi/opportunità da affrontare con la più alta priorità. La scelta è avvenuta con una semplice votazione in stile dot voting (post-it blu piccoli). L’aspetto più interessante è che c’è stato un consenso quasi unanime sui punti più importanti da affrontare. Questo perché la condivisione delle informazioni che avviene durante una sessione di EventStorming porta inevitabilmente ad un forte allineamento nella comprensione delle priorità aziendali.

Questo clustering delle scelte fa sì che ci sia un forte impegno da parte di tutti i partecipanti per la risoluzione dei problemi individuati.
EventStorming è uno strumento molto potente da avere nella propria cassetta degli attrezzi. Dato che la discussione può far emergere alcuni conflitti fra i partecipanti, è fondamentale la presenza di un facilitatore il quale possa coadiuvare il confronto e massimizzare il contributo di tutti i partecipanti.
Process Modeling EventStorming
Il secondo giorno di workshop abbiamo cambiato il focus della nostra analisi. Avendo chiare le priorità aziendali, grazie al lavoro del giorno precedente, abbiamo scelto un problema e lo abbiamo analizzato approfonditamente con l’obiettivo di progettare il software necessario a risolvere il problema stesso. Per fare questo ci siamo avvalsi nuovamente di EventStorming in un’altra variante: Process Modeling. L’ambito di una modellazione di questo tipo può essere un’epica o una feature.
Anche in questo caso gli ingredienti di partenza sono gli stessi, superficie di modellazione ampia, ed eventi di dominio (post-it arancioni), ma con un focus più stretto e un obiettivo diverso: trovare, e progettare, la soluzione ad un problema specifico. Per fare questo siamo partiti creando uno scheletro di eventi di dominio relativi al problema in esame, e poi abbiamo cercato di unire gli eventi costruendo una narrazione consistente utilizzando i seguenti elementi:
- utenti, post-it gialli piccoli, ovvero le persone che interagiscono con il sistema;
- comandi/decisioni/azioni, post-it azzurri, prese dagli utenti in risposta a qualche necessità o stimolo (vedi read model sotto);
- sistemi, post-it rosa grandi, i quali modificano il proprio stato in funzione delle azioni degli utenti;
- eventi di dominio, post-it arancioni, generati dai sistemi in conseguenza ai cambi di stato;
- read model, post-it verde acido, costruiti a partire dagli eventi.
I read model a loro volta possono essere di ulteriore stimolo all’utente per prendere altre decisioni e quindi la modellazione può proseguire seguendo lo stesso schema.
Un’eccezione a questo flusso è costituita dalle logiche reattive che possono essere presenti nel nostro processo. Ad esempio, il sistema può inviare automaticamente una mail dopo che un biglietto è stato venduto, oppure un controllore deve fare una multa a seguito di una verifica fallita. Queste esempi sono entrambi delle policy che devono essere identificate nel processo di modellazione. La differenza fra le due è che la prima sarà implementata nel codice mentre la seconda è una regola che il controllore deve applicare in autonomia ma che comunque fa parte del processo.
Per essere più efficienti nella modellazione, abbiamo prima di tutto definito il caso semplice, ovvero quello in cui l’interazione fra utente e sistema era più lineare. Ad esempio, pensando all’acquisto di un biglietto ferroviario online, dovremmo analizzare prima di tutto il caso in cui c’è posto sul treno, l’utente paga con una carta valida, etc.
Mentre modellavamo il caso semplice, ci siamo segnati le eventuali alternative (e.g. carta di credito non valida) con dei post-it fucsia. Una volta conclusa l’analisi di un flusso siamo tornati sui nostri passi per analizzare l’alternativa più significativa. Questo processo può essere ripetuto finché non si ritiene di aver coperto le casistiche più importanti. Per fare questo tipo di valutazione è sempre utile avere un Product Owner, o comunque un esperto del dominio, che partecipa alla fase di modellazione.
Un aspetto importante che abbiamo cercato di catturare durante questa sessione è stato il valore creato o distrutto, per tutti gli utenti coinvolti, nei vari passaggi della nostra soluzione. Questo è molto importante per verificare che la soluzione individuata per risolvere il problema originale porti, nel suo complesso, un valore positivo al sistema.
Un altro aspetto molto importante di questa sessione è l’attenzione che abbiamo posto nel raffinamento del linguaggio utilizzato. Questo è essenziale per definire chiaramente e senza ambiguità i concetti modellati.
La seconda giornata si è poi conclusa con un approfondimento sul Context Mapping e le relazioni che possono esistere fra i diversi contesti di un dominio: Partnership, Shared Kernel, Customer/Supplier, Conformist, Anticorruption Layer, Open-host Service, Published Language, Separate Ways e Big Ball of Mud. Nel libro DDD Reference di Eric Evans, e su tante altre risorse online, si possono trovare molti dettagli sull’argomento.
Architetture
Il terzo giorno del workshop è stato dedicato ad una carrellata sull’evoluzione delle architetture dalla pubblicazione del primo libro su Domain-Driven Design ad oggi, con un particolare focus su CQRS ed Event Sourcing. È impressionante constatare come il DDD sia rimasto uguale nei suoi concetti fondamentali mentre il modo di costruire le applicazioni e le tecnologie a nostra disposizione sono completamente cambiate. Questo è sicuramente dovuto alla bontà dell’approccio e all’attenzione che viene data alla creazione di un modello che sia privo di contaminazioni da parte dell’infrastruttura e delle tecnologie di supporto.
CQRS e Event Sourcing meritano sicuramente un approfondimento con degli esempi pratici, per cui il mio prossimo post sarà proprio su questi argomenti.
Riferimenti
Approfondimenti su EventStorming


#/media/File:Grey%27s_anatomy_2.png){kind=link}